
Original article (in Serbian) was published on 25/09/2023; Author: Marija Zemunović
A reader asked us to check the statements made by marketing expert Petar Vasic about ChatGPT in a short video posted on Instagram. The video was taken from Milan Strongman’s podcast, where Vasic, as a guest, said the following, among other things:
“When OpenAI was training ChatGPT, it was actually all in English. They do not know, as they have publicly admitted, how it learned Serbian and other languages. It did it by itself. So it looks like it has loosened up a bit. Who knows what is really happening. That Black Box that they call, the neuro network. In fact, we don’t know what’s going on inside. We have input that we give, it goes through the Black Box. And then the output. But we don’t know what it developed there, and we see that it wants to learn some forbidden things. Especially things related to chemistry. Since the fear is for bombs, for things like that. We see that it already knows chemistry, probably at the level of someone who has finished college. Which is very dangerous”.
ChatGPT is a chatbot based on artificial intelligence. It was trained based on a large and varied corpus of texts from the Internet (hundreds of billions of units) and thus “learned” to statistically predict the next word in a sentence. In this way, it more or less successfully responds to user inquiries. We checked the claims made by Vasic about this chatbot, and in the rest of the text, we will try to briefly present what is true and what is not.
ChatGPT and English language
Vasic’s statement regarding “when OpenAI trained ChatGPT, everything was actually in English” can be assessed as incorrect. Although it is not known exactly which units were used to train this system, since there are too many of them, the framework corps are known. The largest among them – Common Crawl – provided 60% of the “tokens”, while, for the sake of comparison, the contents pulled from Wikipedia make up a 12 times smaller part of the corpus. Common Crawl has been collecting material from the Internet for 16 years and is an open repository with 240 billion pages.
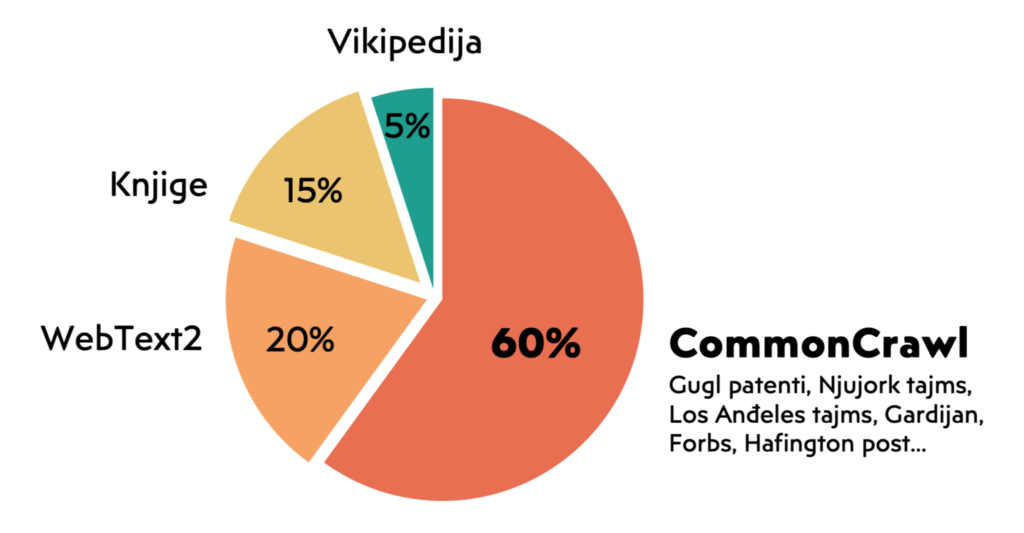
Common Crawl stores texts in different languages, which we could divide into several categories according to the level of participation: languages with high, medium, low and extremely low participation. In this regard, English is a “category by itself”, because it occupies 45-46% of the space. In this sense, we can really say that ChatGPT is biased towards English (like the Internet as a whole). However, other languages are also included in the training material, primarily German, Russian, Chinese, Japanese, French and Spanish – each of them has more than 4% participation.
Serbian is at the bottom of the language category of medium participation (between 0.1% and 1%), after Turkish, Swedish, Arabic, Persian, Korean, Greek, Hungarian and Bulgarian, and ahead of Hindi, Lithuanian and Slovenian. For example, Albanian, Malay, Tamil and Georgian belong to the lowest category, and Scottish Gaelic, Tibetan, Yiddish and Kyrgyz to the lowest. Although the “small” languages occupy a very small part of the corpus, it is still a matter of extensive material that has been incorporated.

To the question “Are you trained exclusively on the corpus of content in English?”, ChatGPT answers no, stating that the corpus also includes content in other languages (Spanish, French, Italian…). The dominant position of the English language is unquestionable. The mentioned bias towards English is noticeable on different levels, from grammatical to cultural. If we ask ChatGPT to write us a rhyming poem in Serbian, to give us an example of a word game or to write some palindrome, we will see that it does not do well, i.e. that – to put it simply – it answers in Serbian, but still “thinks” in English. However, it is also unquestionable that a significant part of the “knowledge” of this chatbot is built based on content from other languages, including some very small ones.
ChatGPT as a black box
When it comes to Vasic’s thesis about the “black box”, that is, the claim that we do not know how this system processes and connects data – it is largely correct. The way this model processes a huge amount of information is not completely known even to its creators. Why? Because the system is set up in such a way that it learns itself how to connect data at one point. Therefore, this process has become too complex to be comprehensively analyzed and deconstructed.
An additional note of mystification is introduced by the fact that the companies that develop AI models are quite secretive when it comes to the mechanisms they implement and test. However, there are researchers who conduct research and ask questions about this system, its functioning and its future.

ChatGPT and bombshell questions
ChatGPT is indeed able to provide answers to questions that it should not be able to answer. Although there is an ethical filter that blocks giving immoral or “dangerous” answers, users have found and are finding various “holes” in the system. One of such “holes” refers precisely to the case when this chatbot was indirectly prompted to provide instructions for making a bomb.
When it comes to the assessment that this system knows chemistry at the level of a university graduate, we can draw attention to two analyzes in parallel. OpenAI wrote about the first one, presenting GPT4. The chatbot managed to solve the chemistry test (AP Chemistry) better than 70% of the real test takers. On the other hand, the research called “ChatGPT also needs a chemistry teacher” is also interesting. It proved that by changing the context it is easily possible to induce ChatGPT to give the wrong answer to a question from an entrance exam for chemistry studies.
